Définition des modèles de génération d’image
Les modèles de texte à image sont des modèles génératifs utilisant l’intelligence artificielle pour produire des images à partir de descriptions écrites, appelées “prompts”. Ces modèles sont de plus en plus populaires en raison de leur potentiel à générer des images créatives et originales. Les données visuelles utilisées pour l’entraînement de ces modèles sont collectées à partir de sources diverses, notamment à partir d’œuvres d’art, de photographies et d’images en ligne.
Quels sont les principaux acteurs ?
Le domaine de la génération d’images est en constante évolution et trois acteurs majeurs y jouent un rôle prépondérant.
- • DALL-E 2 d’OpenAI, la première organisation à avoir fait une démonstration grand public de cette technologie
- • Midjourney, un laboratoire de recherche indépendant offrant une option gratuite d’utilisation du modèle sur le logiciel Discord.
- • Stable Diffusion de StabilityAI, une initiative open-source qui diffuse régulièrement les dernières mises à jour de son modèle.
Ces trois acteurs sont à la pointe de la technologie pour la génération d’images et continuent de pousser les limites de celle-ci. Tous utilisent une technique appelée “diffusion latente” que nous creuserons plus en détail plus loin. Cependant, l’idée derrière cette méthode est d’apprendre à un modèle à recréer des formes familières dans un champ de bruit pur. Ces formes sont modelées progressivement en si elles correspondent aux mots dans le “prompt” grâce à un mécanisme d’attention.

Intuition derrière la génération d’image
Une analogie pour comprendre la tâche que les ordinateurs tentent d’accomplir peut-être exprimée en examinant le raisonnement d’un.e artiste lorsqu’on lui demande de dessiner une oeuvre d’art. Dans ce scénario, nous fournissons à un.e artiste une description plus ou moins précise des caractéristiques de l’objet que nous souhaitons voir dessiner. Ensuite, l’artiste utilise son imagination pour concevoir la manière dont il peut représenter l’objet. Finalement il peut s’exécuter et produire l’oeuvre finale.
Les modèles de génération d’images en intelligence artificielle tentent d’automatiser cette tâche en utilisant le modèle appelé “Transformers” pour générer des images à partir de descriptions textuelles.
Principe de la diffusion
La modélisation générative par diffusion est une technique puissante en intelligence artificielle pour générer des images à partir de bruit pur. Ce processus implique l’application d’un débruitage itératif, à partir d’une image bruitée. En d’autres termes, le modèle apprend à reconnaître des formes familières dans un champ de bruit pur, puis affine progressivement ces éléments s’ils correspondent aux contextes donnés en entrée.
Ce processus de débruitage peut être conditionné avec une image en plus d’une image bruitée en entrée. Cette méthode de conditionnement permet au modèle de tenir compte des informations supplémentaires fournies par l’image, pour produire des images plus précises.
En outre, le processus de débruitage peut également être conditionné avec du texte, ce qui est l’essence du modèle texte à image que nous avons déjà introduit. Cette technique permet de générer des images à partir de descriptions textuelles en utilisant un processus similaire de débruitage itératif.

Principe de la diffusion latente
Les modèles de diffusion latente sont des modèles de diffusion qui au lieu de travailler directement avec une image telle quelle utilisent une représentation de l’image compressée appelée “représentation latente”. L’utilisation de représentations latentes dans les modèles de diffusion permet à ceux-ci de travailler plus efficacement avec des données visuelles ou textuelles, en comprimant l’information en un espace plus petit, tout en préservant les informations clés. De plus, l’utilisation d’une telle méthode conduit à des performances améliorées quant aux temps et aux ressources informatiques nécessaires à la génération d’image.
Travailler dans un espace aussi compressé permet également d’utiliser différents types de données, telles que le texte. Ces représentations peuvent être injectées dans les couches d’attention, qui sont les composants clés des modèles Transformers. Les couches d’attention permettent au modèle d’identifier les parties importantes de l’image ou du texte en entrée, en concentrant son attention sur les zones les plus pertinentes et ainsi générer l’image adéquate.
Mécanisme de la diffusion latente
Pendant le processus d’inférence, le modèle associe des mots avec des images en utilisant une technique appelée CLIP (Contrastive Language-Image Pre-training), qui a été développée par OpenAI. Ce modèle cherche à produire en sortie un vecteur correspondant à l’information latente dans le “prompt” pour aider le processus de débruitage. Une fois ce vecteur produit, celui-ci est passé à travers un réseau de neurones appelé U-Net. Celui-ci est un type spécial de réseau de neurones convolutifs (CNN) d’image à image, utile pour le débruitage itératif. Ainsi, ce réseau de neurones partant de bruit et conditionné avec l’information latente contenu dans le “prompt” dé-bruite progressivement la représentation latente de l’image à générer. Finalement, une fois cette représentation latente dé-bruiter, celle-ci est passée à travers un décodeur pour produire l’image finale.
Importance du prompt engineering
Comme tout modèle génératif, le prompt engineering est une partie importante pour conditionner correctement l’image que l’on souhaite générer. Voici par exemple quelques éléments importants à inclure dans un “prompt” destinés à la génération d’images :
- • Noms des objets : Spécifier les objets que l’on souhaite inclure dans l’œuvre
- • Adjectifs : Utiliser des adjectifs pour décrire le style, la couleur et la qualité de l’œuvre.
- • Noms d’artistes : Calquer le style d’un.e artiste en particulier.
- • Style artistique : Calquer un style artistique, comme “pixel-art”, “fantaisie”, “surréalisme”, “contemporain”
- • Qualité : Spécifier la qualité de l’image, comme “haute qualité”, “4k” ou “8k”
Cette liste n’est pas exhaustive et il existe d’autres techniques plus avancées pour utiliser ces outils.
Affinage d’un modèle pour un usage artistique
Les modèles de diffusions stables peuvent être, comme les autres types de modèles de fondation, affinés pour effectuer une tâche en particulier. Dans le cas du texte à image, cela peut être très pertinent si l’on veut explorer certaines possibilités artistiques tout en suivant le style graphique de personnage déjà existant.
Nous pouvons illustrer cette adaptation en faisant apprendre à notre modèle par exemple le style graphique des Pokémon. En ajoutant des “prompts” associées à chaque Pokémon, il est ainsi possible de demander au modèle de générer de nouvelles créatures.

Exemple d’autres usages
En plus de sa fonction de base, qui permet de créer des images à partir de texte, la diffusion stable a d’autres cas d’utilisation passionnants.
L’un de ces cas est la retouche d’images. En effet, grâce à une technique d’outpainting, la diffusion stable peut être utilisée pour restaurer des images endommagées en recréant les parties manquantes à l’aide de l’IA. Il est également possible, en utilisant une technique d’inpainting, d’intégrer des éléments à l’intérieur d’une image pour améliorer son apparence.
Dans le futur, il sera possible à partir de texte de générer et non plus seulement des images, mais également des contenus vidéo. Cette fonctionnalité révolutionnaire a été en effet démontrée par l’entreprise Meta vers la fin de l’année 2022.

Considération éthique
Bien que les possibilités de l’utilisation de cet outil sont impressionnantes. Celui-ci soulève plusieurs préoccupations éthiques et légales, notamment autour de la propriété intellectuelle.
Par exemple, bien que l’outil dispose d’un filtre pour bloquer les images inappropriées, il peut être facilement contourné, ce qui peut causer des problèmes pour la protection de la vie privée et la sécurité en ligne.
De plus, l’utilisation de l’outil pour imiter le style d’artistes existants peut soulever des questions sur la propriété intellectuelle et les droits d’auteur. Par exemple, le 26 août 2022, une œuvre générée par une intelligence artificielle a gagné un concours de beaux-arts au Colorado aux États-Unis. Ce scandale a permis de nous rappeler que l’influence de ces outils dans le milieu artistique est disruptive et ne doit pas être prise à la légère.
Enfin, les images réalistes créées par cet outil peuvent être utilisées à des fins dangereuses, telles que la propagande ou la désinformation. En effet, ces images peuvent être utilisées pour usurper l’identité de quelqu’un, ce qui peut causer de gros problèmes éthiques. Dans le futur il sera donc important de mettre en place des systèmes de vérification pour s’assurer que les images générées soient authentiques.
]]>Les enseignants cherchent toujours des moyens d’engager et de motiver leurs élèves, et la technologie de génération d’images IA peut être un outil précieux pour y parvenir. Dans cette vidéo, Élianne et Daniel explorent deux moteurs de génération d’images, DALL-E 2 et MidJourney, et présentent quelques exercices pour les intégrer dans l’éducation.
DALL-E 2 est un outil en ligne facile d’accès qui permet de générer rapidement des images en entrant quelques mots clés. Cependant, les résultats peuvent varier en fonction de la précision de la description. MidJourney, accessible via Discord, offre un rendu plus artistique et magique par rapport à DALL-E 2. Ces moteurs peuvent aider les enseignants à créer des supports visuels attrayants et mémorables pour les cours.
Élianne et Daniel présentent trois exemples d’exercices pour intégrer la génération d’images dans l’enseignement:
- 1. Explorer les courants artistiques: en modifiant légèrement la requête, MidJourney peut générer des images dans différents styles artistiques, tels que le cubisme ou l’art optique.
- 2. Visualiser la poésie: en utilisant des extraits de poèmes ou de chansons comme requêtes, MidJourney peut générer des images intéressantes et variées qui peuvent être utilisées comme supports visuels dans les présentations.
- 3. Représenter visuellement des concepts théoriques: en créant des images pour des concepts scolaires, les enseignants peuvent aider les élèves à mieux mémoriser et comprendre certains themes. Par exemple, représenter une crevette avec des gants de boxe.
Les enseignants peuvent également jouer avec les paramètres et les commandes de MidJourney pour influencer les résultats des images générées. Le paramètre Blend, par exemple, permet de fusionner deux à cinq images pour créer des résultats amusants et ludiques.
Dans cette courte vidéo, apprenez comment vous pouvez vous-même commencer à utilser MidJourney!
]]>Qu’est-ce que maîtriser le langage ?
Si l’on devait faire une analogie avec la linguistique, les langues sont apprises et enseignées à partir de 4 compétences langagières de base :
- • Compréhension écrite (modèles de compréhension)
- • Compréhension orale (modèles de compréhension)
- • Expression écrite (modèles d’expression)
- • Expression orale (modèles d’expression)

Comment l’ordinateur et l’humain comprennent-ils le langage ?
En comparaison avec les machines, l’acquisition du langage chez les êtres humains se déroule différemment. En effet, les humains peuvent comprendre celui-ci avant même de savoir lire. Cela signifie que, dès leur plus jeune âge, ils sont capables de communiquer sans nécessairement connaître les règles grammaticales. Au fil du temps, ceux-ci apprennent à transformer leur langage oral en langage écrit, leur permettant ainsi de lire et d’écrire. Une fois qu’ils ont maîtrisé la lecture, ils peuvent apprendre à reconnaître des mots qu’ils connaissaient déjà uniquement à l’oral.
Les machines, quant à elles, ne sont pas capables d’interpréter le langage de cette façon. Les chercheurs doivent donc développer des systèmes qui leur permettent de traiter le texte sans avoir la capacité, comme les humains, de relier les sons à la signification des mots. Ainsi, ces systèmes doivent être bâtis sur des méthodes qui n’ont pas de connaissance préalable du langage. Cela crée le dilemme classique de “la poule et l’œuf” : comment les machines peuvent-elles commencer à traiter du texte si elles ne connaissent rien à la grammaire, aux sons, aux mots ou aux phrases.
La solution est d’utiliser ce que l’on appelle des modèles de langage. Ces modèles sont en quelque sorte des cerveaux numériques qui comprennent le langage humain et permettent aux machines de réaliser certaines tâches telles que la:
- • Traduction automatique
- • Reconnaissance de la parole
- • Récupération de l’information
- • Génération d’articles de presse
Compréhension de l’ordinateur
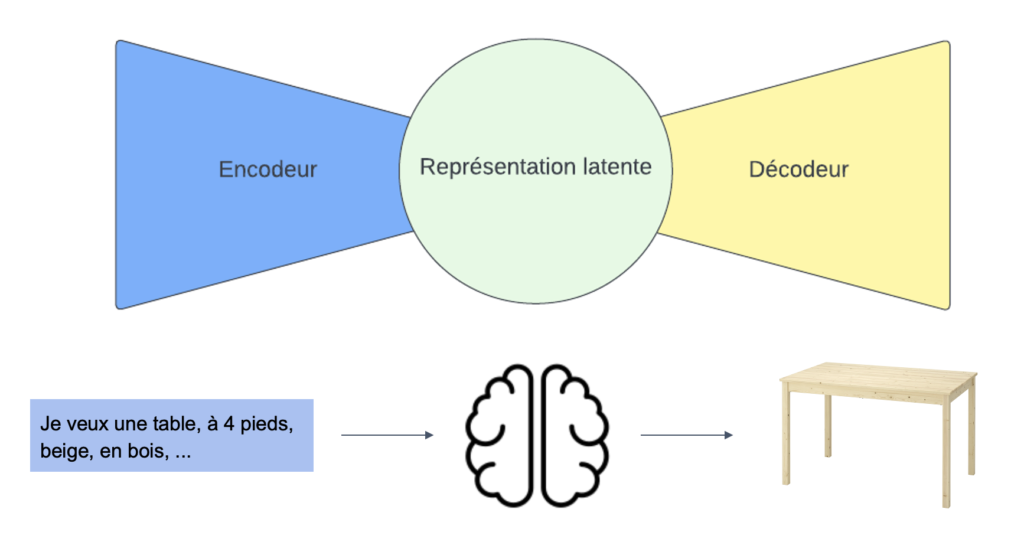
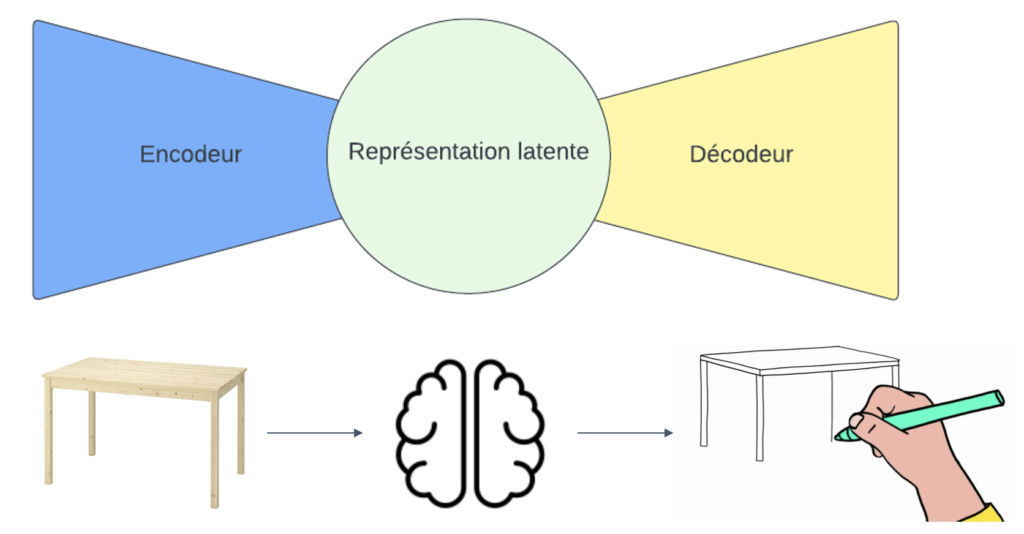
L’architecture utilisée pour que l’ordinateur apprenne et maîtrise notre langage est composée d’un encodeur et d’un décodeur. Pour mieux comprendre ce processus, il est possible de réaliser une expérience de pensée :
- 1. Tout d’abord, choisir un objet dans l’environnement proche et le fixer du regard pendant une dizaine de secondes
- 2. Ensuite, imaginer cet objet dans sa tête.
- 3. Finalement, prendre un crayon et essayer de dessiner cet objet.
Concrètement nous venons de (1) encoder l’objet dans ta tête, (2) se l’imaginer en représentation compressée que l’on appelle aussi représentation latente, (3) décoder l’objet sur papier.
Ce processus permet de comprendre comment un ordinateur apprend et utilise un modèle de langage. Lors de cette expérience de pensée, l’objet est d’abord encodé dans la tête de la personne (1), puis il est imaginé dans une représentation compressée, également appelée représentation latente (2). Enfin, l’objet est décodé sur le papier (3). C’est exactement comme ça qu’un ordinateur apprend et utilise un modèle de langage.
La représentation latente représente une version compressée de l’image de l’objet. C’est à ce niveau que l’on peut puiser dans sa base de connaissances pour établir des liens avec l’information qui a été encodée.
En pratique, au lieu de montrer un objet, il est possible de donner une description plus ou moins précise de ses caractéristiques. La personne essaiera alors de s’imaginer l’objet avant de le dessiner. On peut répéter cette logique avec toutes sortes de systèmes de signes.
Modèles de langage
La même logique peut être appliquée pour le traitement du langage naturel. Dans le cas de la traduction, l’architecture encodeur-décodeur peut être comparée à deux traducteurs humains qui parlent seulement deux langues : leur langue maternelle et une langue imaginaire qu’ils ont en commun. Par exemple, s’ils parlent l’allemand et le français, l’encodeur convertira la phrase allemande en la langue imaginaire qu’ils partagent, et le décodeur pourra alors traduire la phrase en français. Cette approche permet de traduire des phrases d’une langue à une autre en utilisant une langue intermédiaire commune. Cette méthode est utilisée dans les systèmes de traduction automatique qui sont basés sur des modèles de langage et des algorithmes d’apprentissage automatique.
Il est également possible d’utiliser cette architecture encodeur-décodeur pour d’autres tâches, comme la génération de textes. Par exemple, l’encodeur pourrait fournir un contexte et le décodeur serait responsable de produire un article de presse.
Transformers
L’architecture Transformer a été développée par Google en 2017. Elle permet d’entraîner notre fameux modèle de langage. Cette architecture utilise un encodeur et un décodeur, comme introduit précédemment. Toutefois, elle intègre un nouveau mécanisme appelé l’attention pour permettre à l’ordinateur de mieux comprendre le contexte d’une phrase. En effet, les méthodes précédentes avaient des limites de mémoire qui ne permettaient pas de comprendre le contexte complet d’une phrase.
Les Transformers ont connu un succès fulgurant en raison de leur efficacité à traiter le texte et ont établi de nouveaux standards en termes de performance. Cette architecture a permis des avancées significatives dans le domaine de la compréhension du langage naturel, notamment autour de la traduction automatique et de la génération de texte. Les modèles de compréhension et d’expression sont deux applications clés de ces modèles,
Les modèles de compréhension
Les modèles de compréhension utilisent la portion encodeur d’un modèle de langage. C’est comme si l’on donnait à un humain un texte et qu’on lui demandait de faire des tâches directement sur ce texte. Le modèle le plus connu est BERT.
Les modèles d’expression
Les modèles d’expression (ou modèles génératifs) utilisent la portion encodeur puis décodeur d’un modèle de langage. C’est comme si l’on donnait à un humain un contexte et qu’on lui demandait de créer du contenu à partir de celui-ci. Le modèle le plus connu est GPT-3 aussi utilisé par ChatGPT.
Comment ces modèles sont-ils entraînés ?
Les modèles de compréhension
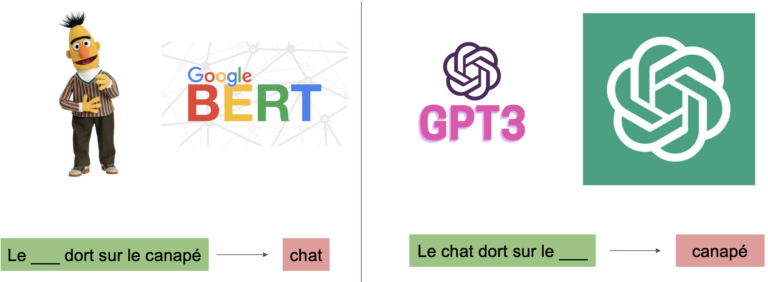
Afin de comprendre un texte, il est important de comprendre les mots qui le composent ainsi que leur contexte. C’est l’idée qui est utilisée ici pour les modèles de compréhension. Le modèle reçoit une séquence de mots et doit prédire le mot manquant dans la séquence en se basant sur le contexte fourni par les mots environnants.
Exemple :
Le _ dort sur le lit => “chat”
Dans ce processus, le modèle a ainsi été entraîné à prédire le mot manquant en se basant sur les motifs qu’il observe dans les données.
Les modèles d’expression
Afin de générer un texte, il est important de comprendre le contexte et les consignes d’écriture. C’est l’idée qui est utilisée ici pour les modèles d’expression. L’objectif de l’entraînement est de prédire le prochain mot dans une séquence de mots en se basant sur le contexte fourni par les mots précédents.
Exemple :
Le chat dort sur le => “lit”
Lequel de ces deux types de modèles est le meilleur ?
Le choix entre les modèles de compréhension et les modèles d’expression dépendra de la tâche à accomplir, il n’y a pas de modèle supérieur à l’autre. Les modèles d’expression, tels que GPT-3, sont souvent utilisés pour aider à la création de contenu, comme c’est le cas avec ChatGPT. En revanche, pour des tâches plus précises comme la réservation de billets d’avion en ligne, un modèle de compréhension serait plus adapté. ChatGPT pourrait fournir un guide pour les étapes à suivre, mais ne pourrait pas effectuer la réservation elle-même.
En fin de compte, le choix du modèle dépendra des besoins spécifiques de chaque tâche. Les modèles d’expression peuvent être utiles pour la créativité, tandis que les modèles de compréhension peuvent être plus adaptés à des tâches spécifiques nécessitant une compréhension précise du texte.
Les modèles de langage, tels que BERT ou GPT-3, sont entraînés sur des quantités massives de données provenant d’Internet. Cela leur confère une bonne performance sur des tâches d’ordre général, mais pas forcément sur une tâche spécifique.
En effet, ces modèles sont comparables à un médecin généraliste dans le domaine médical. Ils peuvent répondre à de nombreuses questions en surface, mais ne peuvent pas rentrer dans les détails de chaque sujet. De même, ChatGPT peut donner de bons conseils généraux, mais ne pourra pas nécessairement répondre en profondeur à des questions plus spécifiques.
Comment améliorer les performances d’un modèle sur une tâche en particulier ?
Lorsque l’on utilise un modèle de langage de base comme BERT ou GPT-3, les performances sur des tâches spécifiques peuvent ne pas être optimales malgré une bonne performance globale. Cependant, il est possible d’améliorer les performances sur une tâche en particulier grâce à la technique d’affinage des modèles. Cette technique consiste à prendre le modèle de base et à l’adapter à une tâche ou à un domaine de connaissance spécifique.
Pour reprendre l’analogie du médecin, c’est comme si on prenait un médecin généraliste et qu’on lui demandait de devenir dermatologue. Concrètement, comment cela se passe-t-il en intelligence artificielle ? Il va falloir affiner nos modèles avec des données spécifiques à la tâche ou au domaine que l’on souhaite couvrir. Par exemple, en fournissant uniquement à notre modèle généraliste des articles de dermatologie, celui-ci deviendra meilleur à générer des diagnostics pour les patients.
Ainsi un industriel qui possède des données privées sur un domaine en particulier peut obtenir un avantage stratégique sérieux simplement en affinant un modèle avec ses données. Il pourra ainsi innover plus rapidement dans son secteur et prendre un avantage concurrentiel à ne pas négliger, notamment dans un contexte de pénurie d’emploi.
Le nouveau paradigme en intelligence artificielle repose sur la notion d’affinage des modèles. Les modèles fondamentaux sont comme de gros cerveaux entraînés avec une grande quantité de données sur différents sujets. Ce modèle peut finalement être adapté à de nombreuses tâches particulières.
]]>